these models came step-by-step to fix problems
Good question 👍 — these models came step-by-step to fix problems of the previous ones.
I’ll explain the exact improvement + why it was needed in simple flow so you can revise fast.
🧩 1️⃣ Rule-Based Systems (Before Deep Learning)




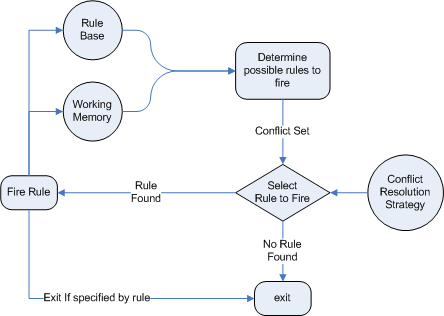
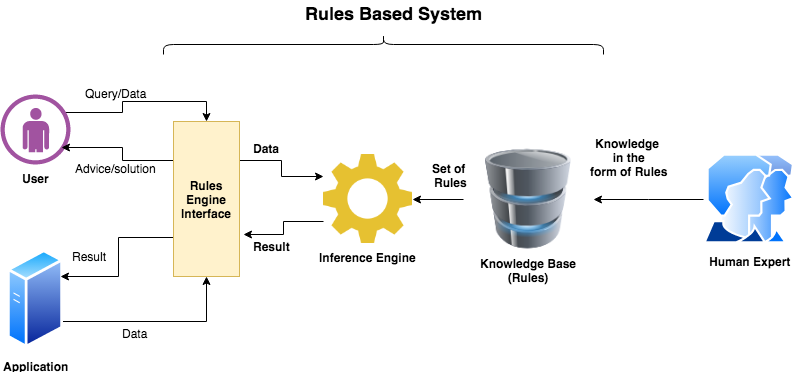
✅ What it is
Hard-coded logic: IF condition → THEN action
Example:
IF fever + cough → suggest cold medicine
❌ Problems
No learning from data
Not scalable
Breaks with new situations
👉 Why new models were needed: Real world language & time-series are complex — rules cannot capture patterns.
🔁 2️⃣ RNN (Recurrent Neural Network)

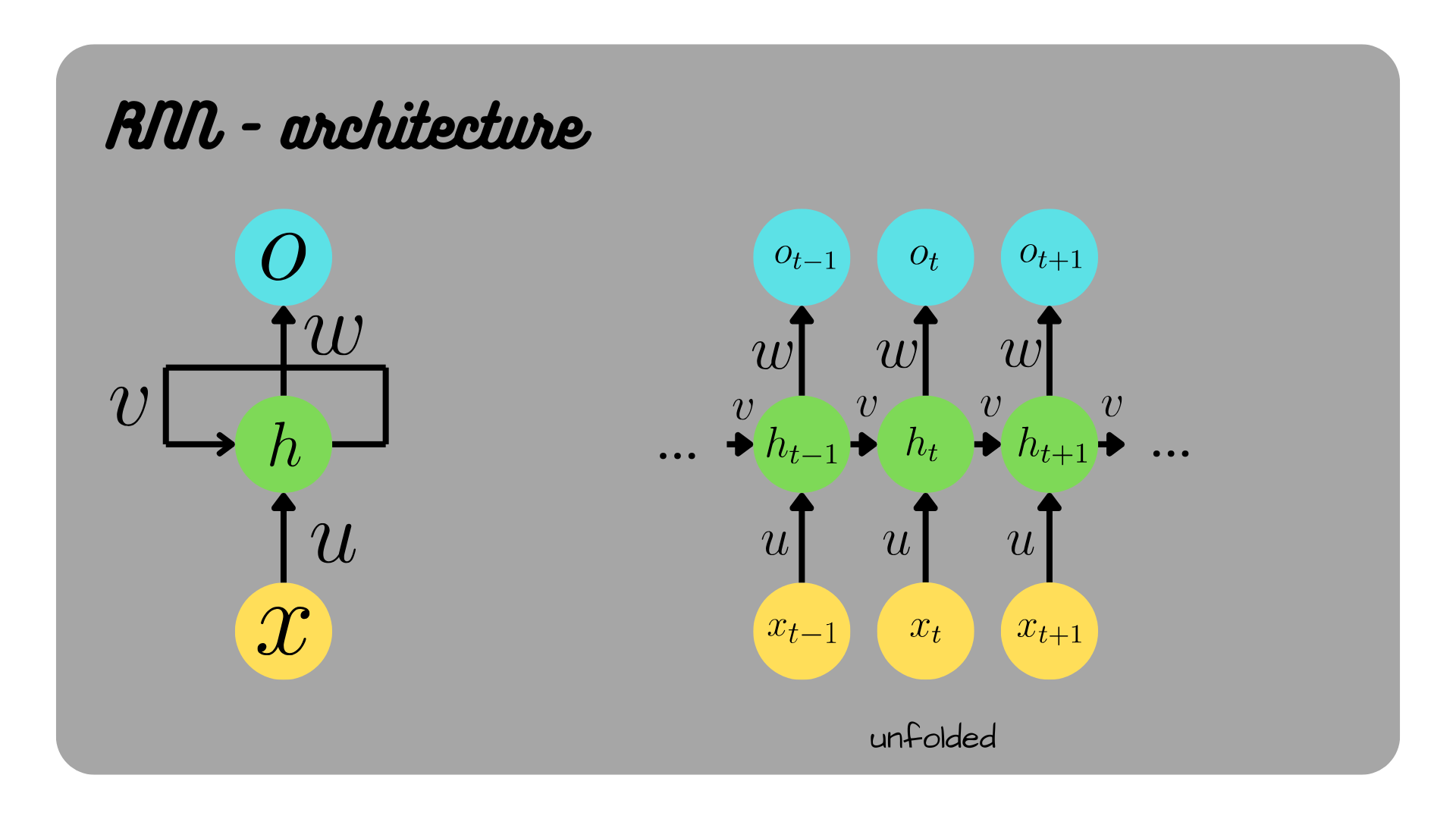
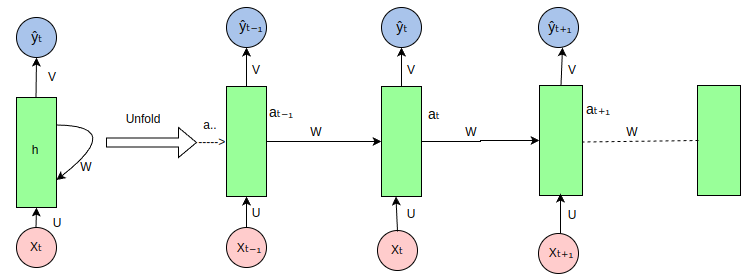

✅ Improvement over Rule-Based
Learns from sequential data (text, speech, time series)
Has memory via hidden state
Uses previous output as input
👉 Example:
“I love AI because ___”
RNN remembers earlier words.
❌ Problems
Vanishing gradient problem
Cannot remember long sequences
Training slow
👉 Needed something with better memory control.
🧠 3️⃣ LSTM (Long Short-Term Memory)
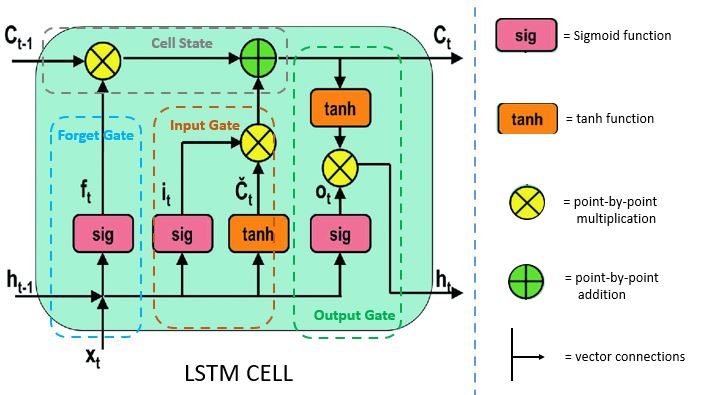

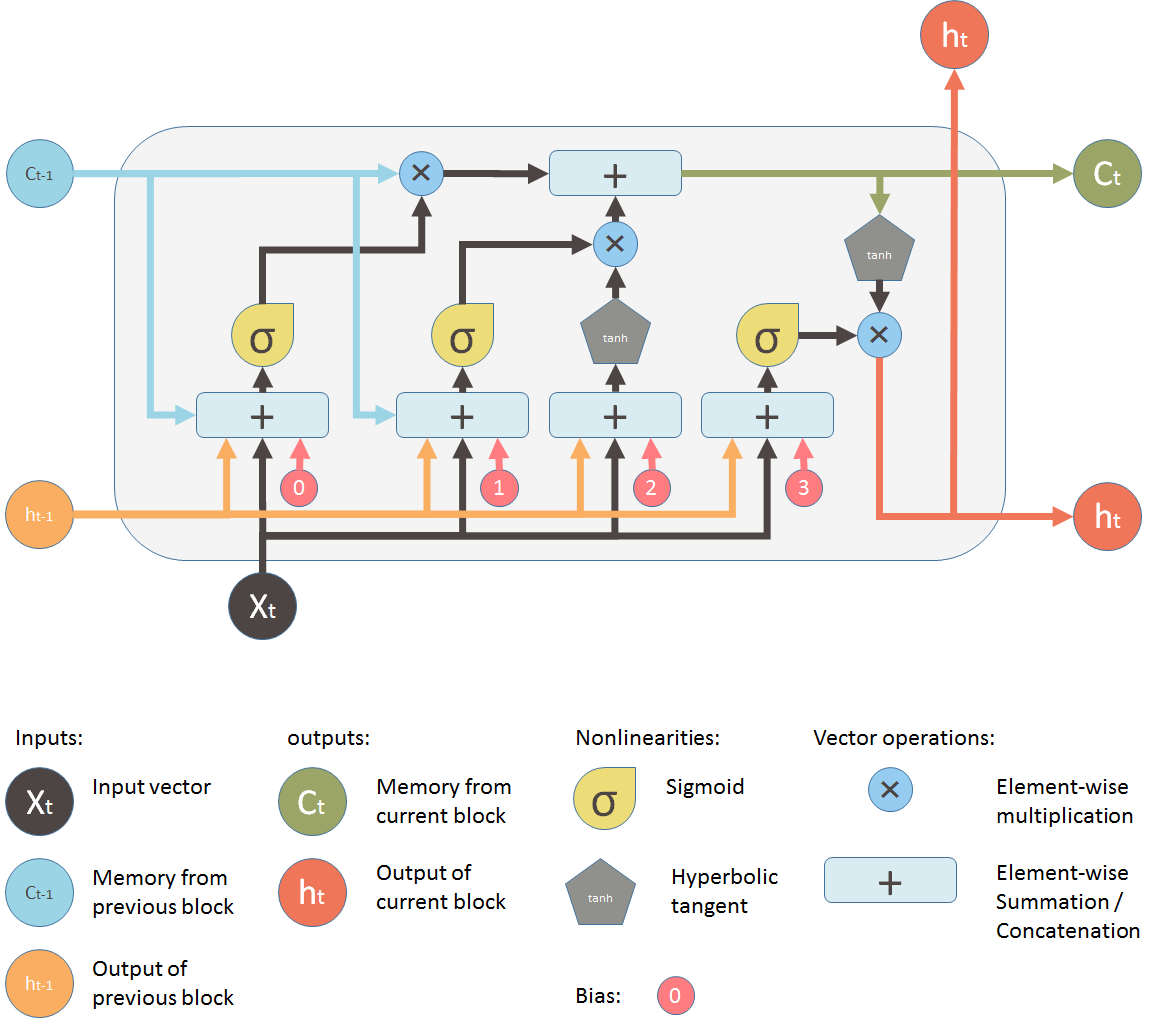

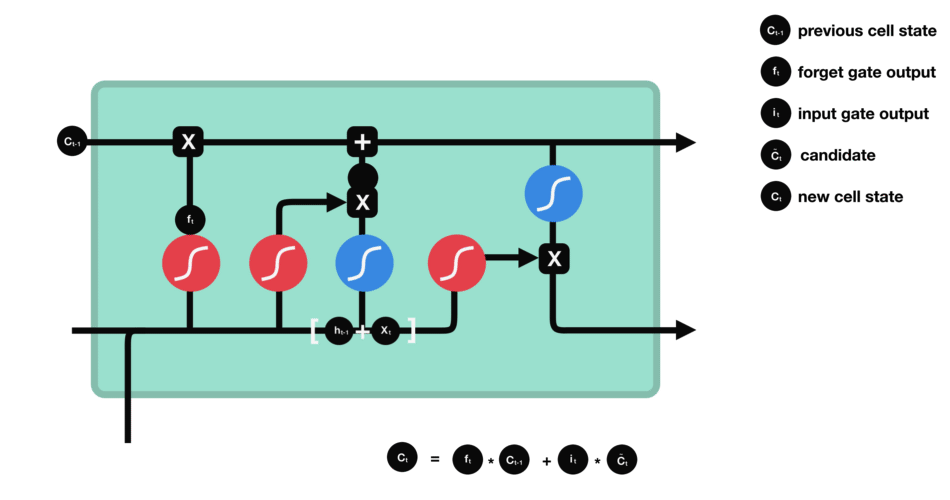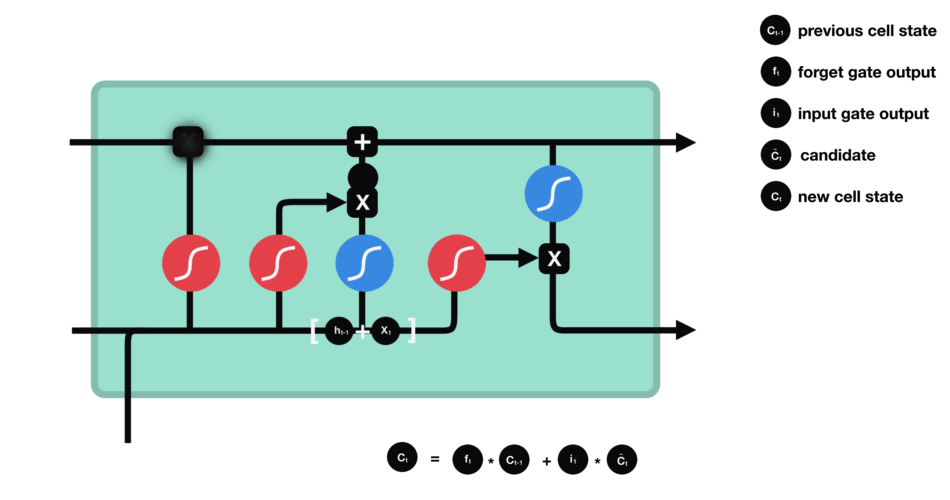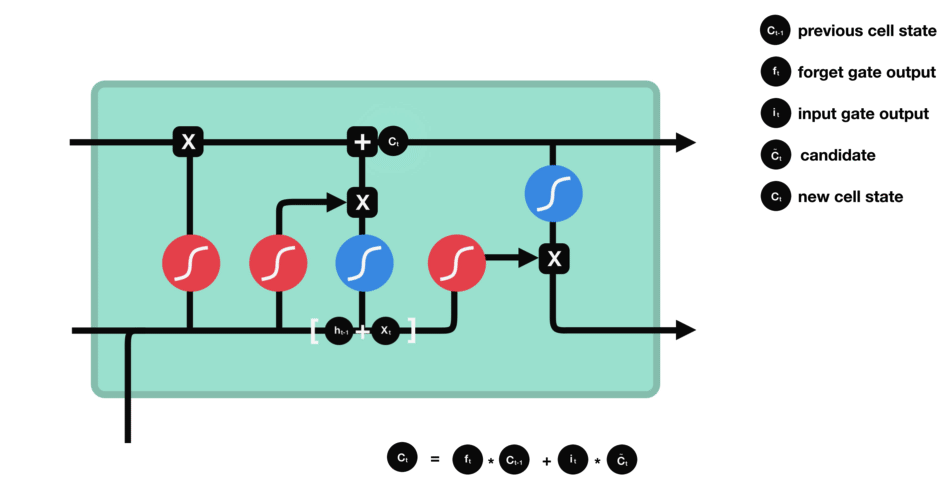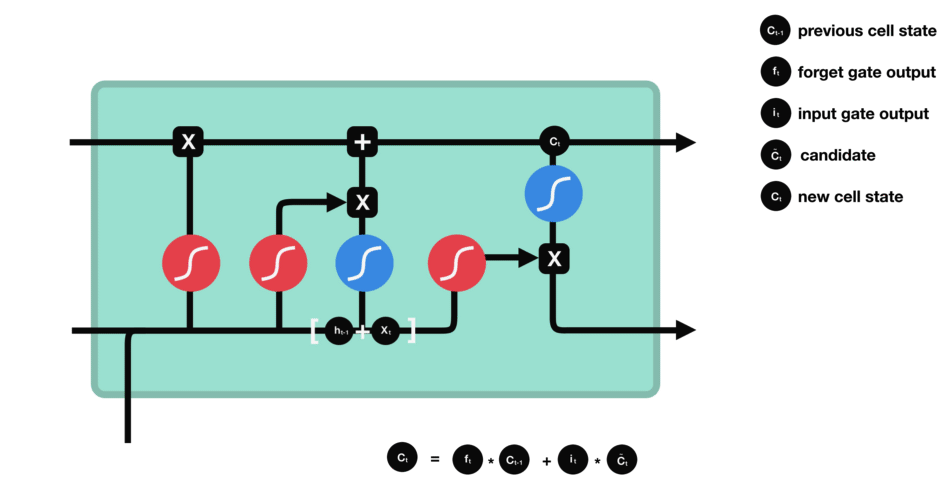
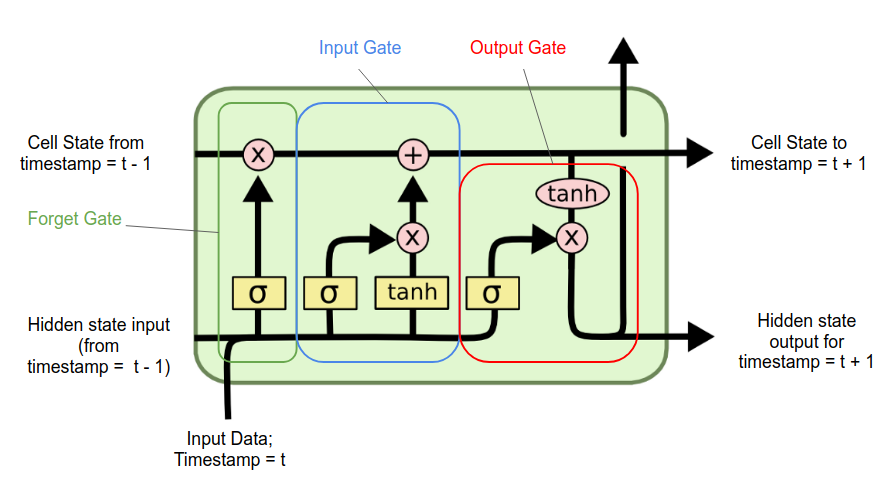
✅ Improvement over RNN
Adds gates to control memory:
Forget Gate → remove useless info
Input Gate → add new info
Output Gate → decide what to show
✔ Why Needed
Fix long-term memory issues
Better for long sentences & sequences
❌ Problems
Heavy computation
Many parameters
Slow training
👉 Researchers wanted faster model with similar power.
⚡ 4️⃣ GRU (Gated Recurrent Unit)
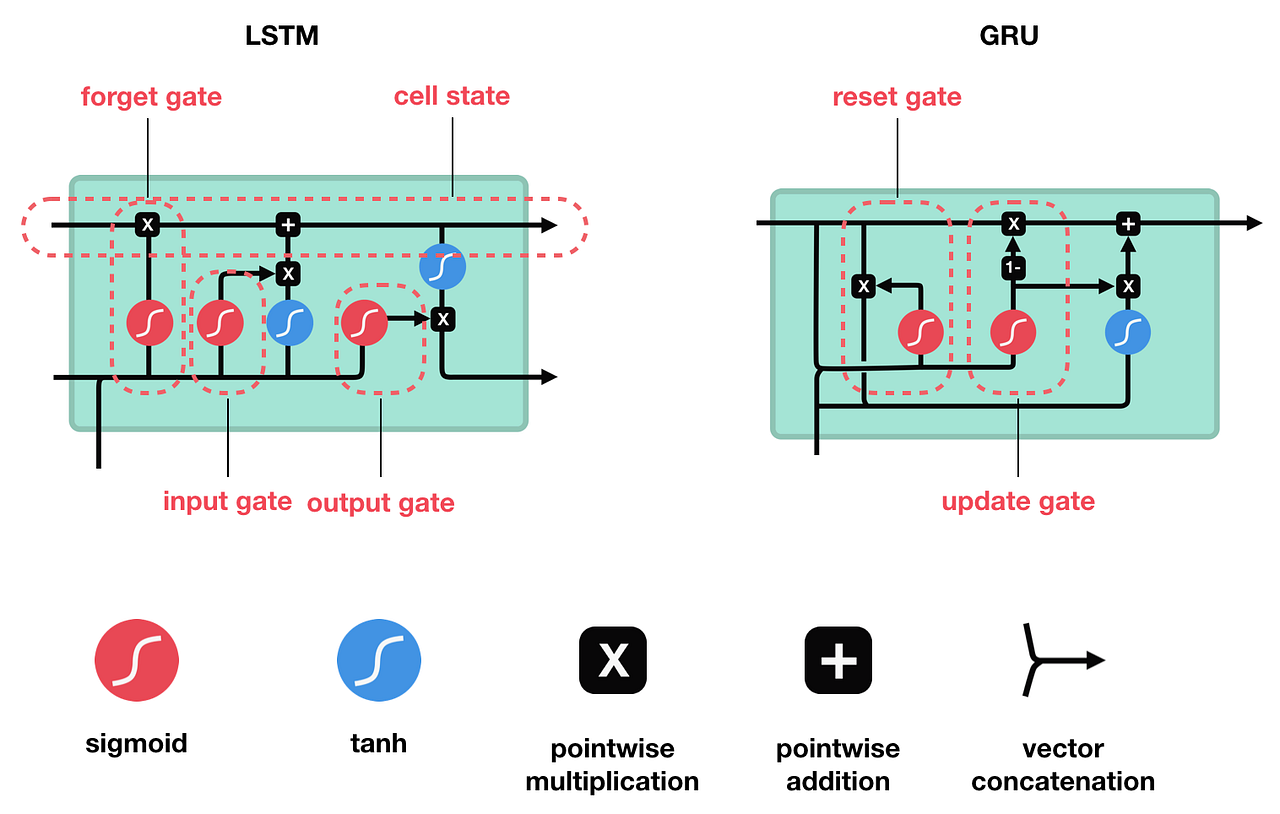





✅ Improvement over LSTM
Combines gates → simpler design
Fewer parameters
Faster training
✔ Why Needed
Reduce complexity of LSTM
Good performance with less computation
❌ Still a Problem
Processes words one by one (sequential)
Hard to parallelize → slow for big data
👉 Needed a model that reads entire sentence at once.
🤖 5️⃣ Transformer (Modern AI – GPT, BERT, etc.)

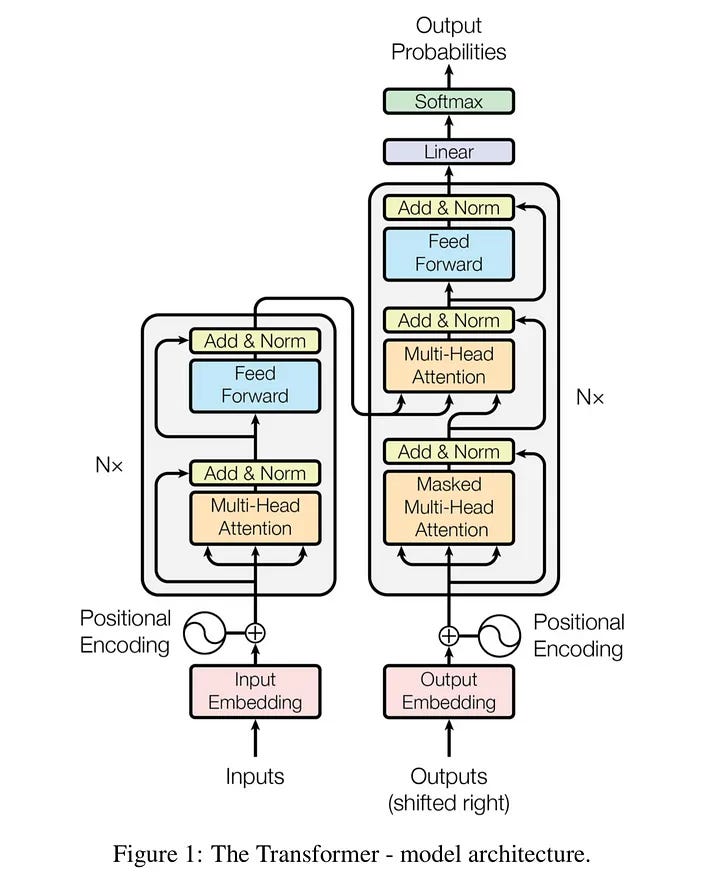
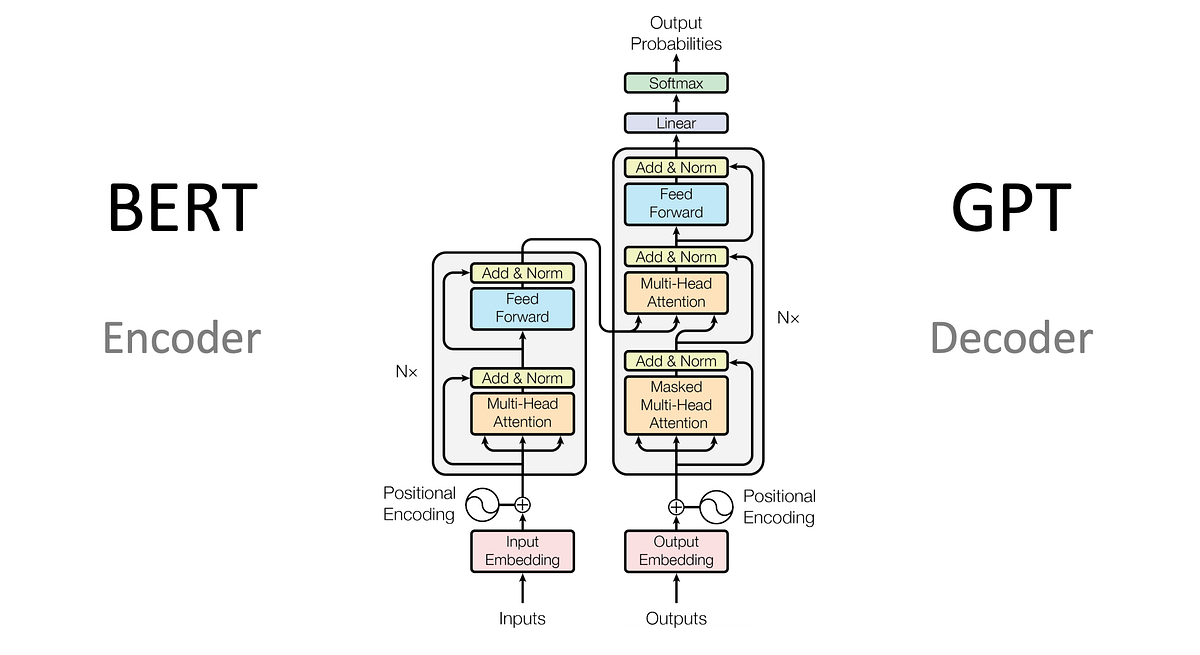

✅ Biggest Improvement
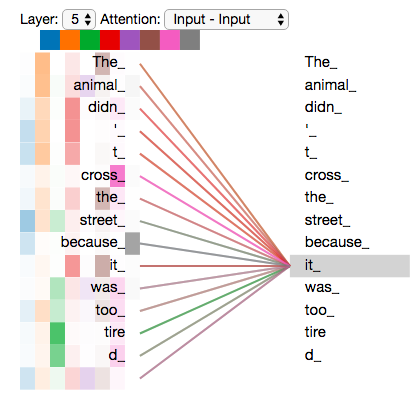
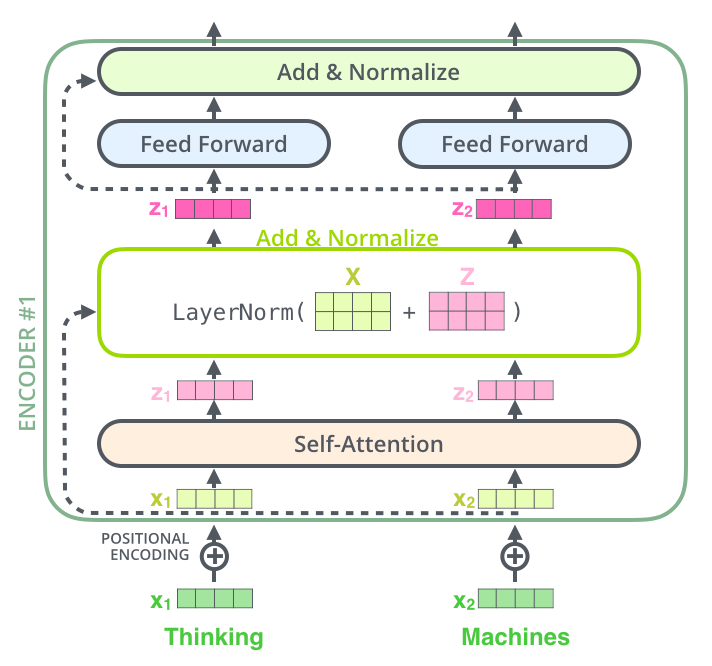
Introduced Self-Attention Mechanism:
Looks at all words simultaneously
Understands relationships between distant words
✔ Why Needed
RNN/LSTM/GRU were slow and sequential
Transformers allow:
Parallel training 🚀
Long context understanding
Huge scalability (ChatGPT, Gemini)
🔥 Result
State-of-the-art NLP & AI
Basis of LLMs (Large Language Models)
🧾 Quick Exam Revision Table (Very Important)
| Model | Main Idea | Improvement | Problem Solved |
|---|---|---|---|
| Rule-Based | IF-THEN logic | Deterministic decisions | No learning |
| RNN | Sequential memory | Learns patterns | Handles sequence |
| LSTM | Gates memory | Long-term learning | Vanishing gradient |
| GRU | Simplified LSTM | Faster & lighter | Efficiency |
| Transformer | Self-Attention | Parallel processing | Speed + long context |
If you want, I can also give you:
✅ One SUPER SHORT 10-line revision (perfect for viva & placements)
✅ OR a diagram-style comparison you can directly use in your project report / AI notes.
Comments
Post a Comment